Event Driven Architecture
🏠 A small SaaS project for IoT
📌 About This Project
This is a personal project and a proof of concept to learn and implement Event Driven Architecture using Python, RabbitMQ, and Kubernetes.
Compilations and Workflow status
💡 Main idea
A simple excuse learn and use Python as Pub/Sub and a message broker, in this case RabbitMQ, to provisioning infrastructure triggered by event like "buy a small module" and finally monitoring all infrastructure. I love IoT, for this reason, this PoC is designed to simulate a "SasS Product". At the end of all this, it will provision my small IoT modules. 👾The project has two big "blocks"
● First: Base infrastructure. Kubernetes over AWS EC2 and all deployed with Terraform and Ansible.
● Second: Kubernetes architecture, APIs, Services, Databases and more endpoints all deployed in Kubernetes with Helm using my own Helm-charts
🔥 Supposed problem
💀 I need to manage a lot inputs, all of them, will be to do different tasks, like messages, deployments, and more. Obvioulsly I will re-use data to make another jobs generate custom events, and finally ,will be use Grafana to see some analysis and tendences.
💀 Some apps have to get information but a common problem is have or develop lot of products in with different technologies like, NodeJs,Python,Php.
💀 I would like to have a shared origin to get data and avoid RE-build or make connectors or apis for connect different components in different tech/languages.
💀 All developers need to know what version must be fixed, or I need a human resource to manage version number. (I would like avoid manage it manually).
🏁 Objetive
● The same scenario must be able to be reproduced multiple times.
● Full project (or almost all) need to be a code ( or/and IaaC).
● Create a simple api to centralize all "inputs" and organize work-loads by queues.
● Each microservice consume his our queue and if need, can consume others to.
● Each microservice do a specific tasks, this is to avoid have "JUMBO-Pods".
● All microservice generate logs for future monitoring, analysis and make improvements or troubleshoot.
● All logs must to be expose in stdout, to avoid write data in the container. This way enable me to use my pods with ReadOnly Filesystem.
● Automate All tasks via microservice API-CALL environments.
● Generate a big scalability and security isolating each tasks in small actions/calls.
● Avoid tech dependences or "human-tech dependence". Each human can enjoy his own Tech/Language.
● The standard (input/output) will be
● To manage version numbers I created a
🛡️ Minimum security
● Safe data: My apps use tokens or passwords, and I need to manage them safely and then I need to commit all data without leaking my secrets.
● Vulnerability Scans: Every time a Developer or SRE build a docker image must be scanned to find possible vulnerabilities. If it happen that image have to mark with different tag.
➤ See examples:
🔍 Monitoring
● Monitoring: All developers or devops must be see some metrics. (PLG Stack)
🎁 Extra feature
● Vendor-neutral: In my case, I prefer have a infrastructure can be used and implemented in any cloud provider that runs a kubernetes cluster, in an "on-premise" client environment or even in a development environment, like my laptop.
Infrastructure design and workflow
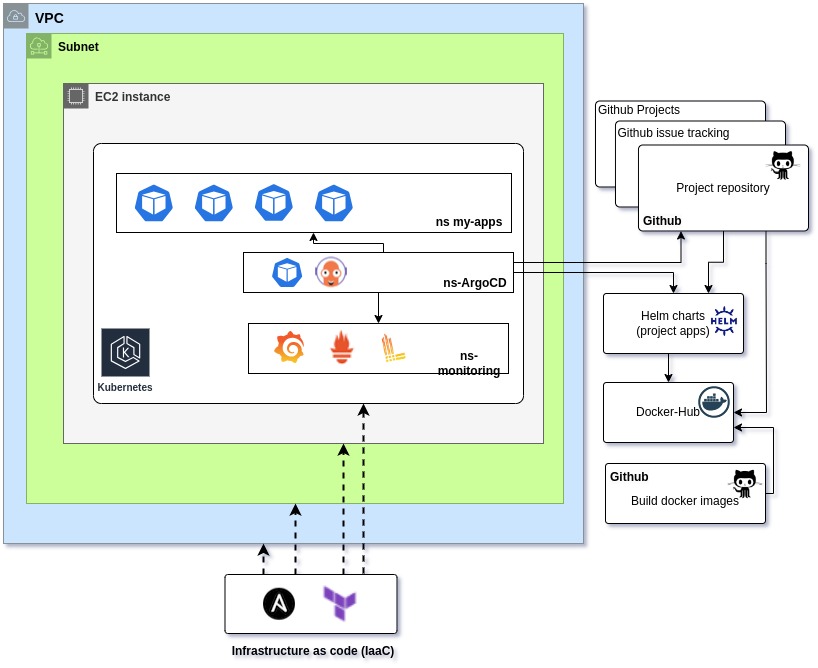
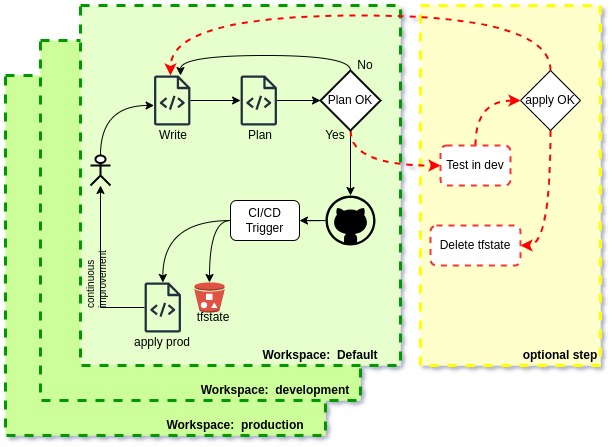
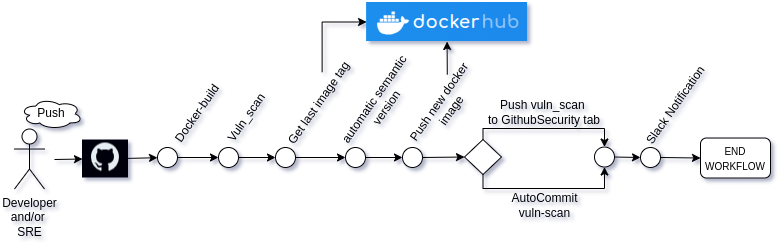
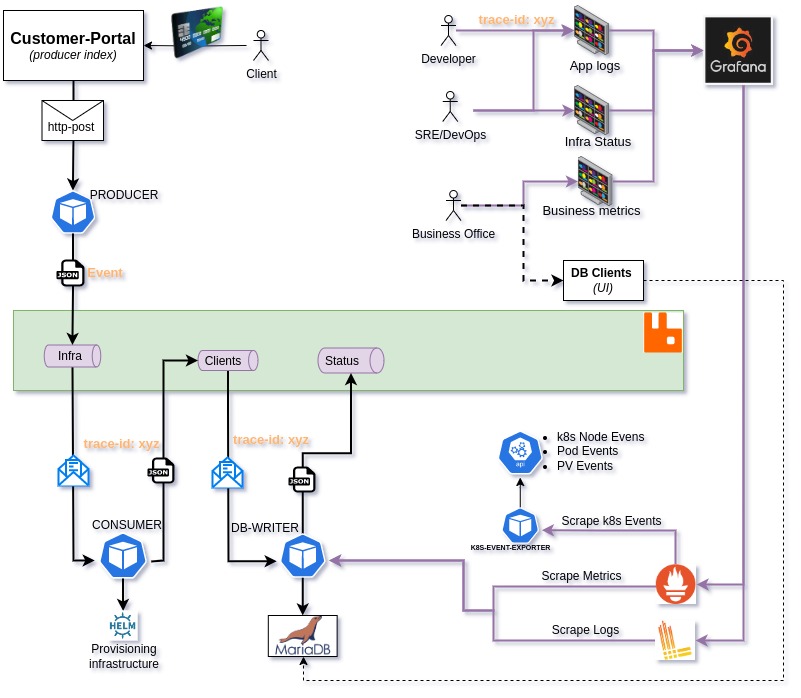
Architecture
Json data model (example)
{
"client":"cliente02", /* Client Name or Identification */
"namespace":"cliente02", /* kubernetes namespace = client */
"environment":"Development", /* Dev / Stage / Prod */
"archtype":"SaaS", /* SaaS / Edge / On-Prem */
"hardware":"Dedicated", /* Classic (No extra cost allocated) / Dedicated (Extra cost allocated) */
"product":"Product-A", /* Product-A / -B / -C / -N */
"MessageAttributes": {
"event_type": {
"Type": "String",
"Value": "mycompany.producer.event.client.published" /* (Dinamic) Company.App.messageType.client.EventAction */
},
"published_on": "2023.01.2.23.02.642883101", /* +%Y.%m.%d.%H.%M.%N */
"trace_id": "9a2ae9de-3f82-4f55-966b-47df50ff51ff", /* uniq random string */
"retrace_intent": "0" /* how many reintents */
},
"Metadata": {
"host": "hostname", /* microservice */
"origing": "Cloud", /* Cloud / On-Prem */
"publisher": "producer" /* publisherType */
}
}
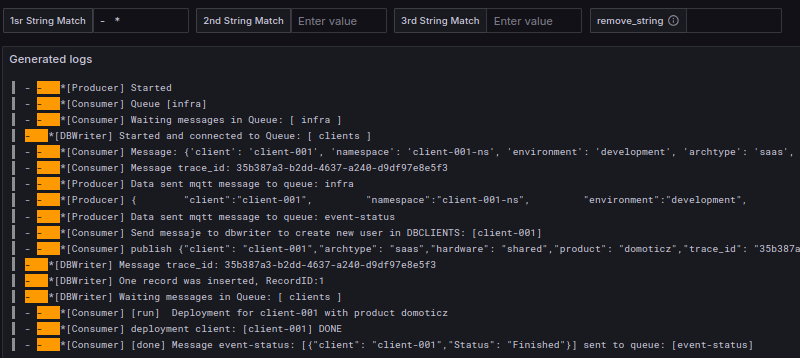
TraceID from deployment workflow to pod annotations
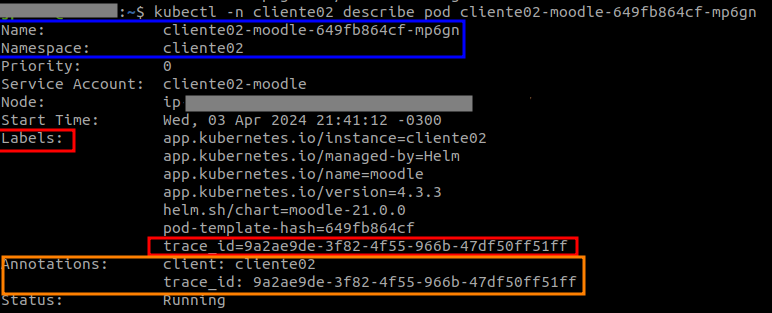
This trace_id is super usefull when you need to see the deployment trace, and then I use it like reference tag and/or annotations in pods.
trace_id is generated on first api-call in deployment process and is allocated to all the pods. If you use grafana or similar you can trace all steps and associate it to deployment or even in each pod deployed with this process
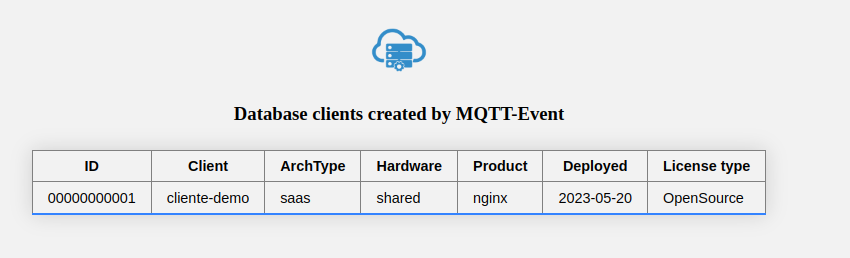
DBClients UI (webserver)
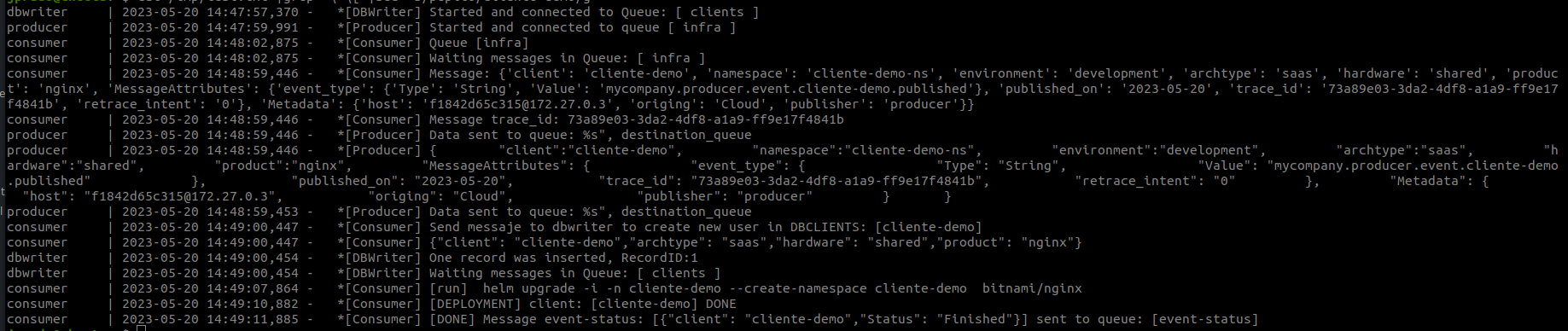
Kubernetes Logs

Grafana Dashboards
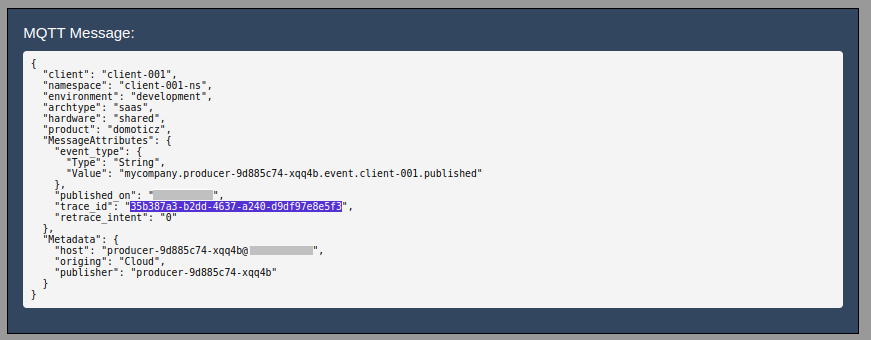

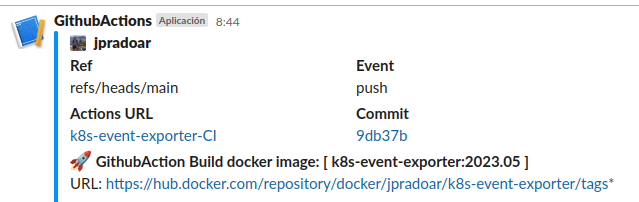
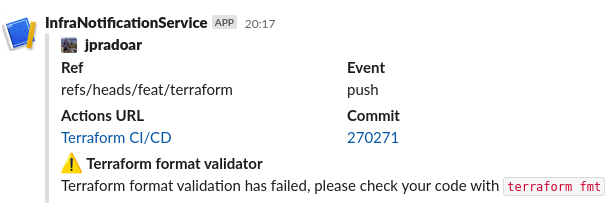
Alerts and Messages

{
"client":"cliente02", /* Client Name or Identification */
"namespace":"cliente02", /* kubernetes namespace = client */
"environment":"Development", /* Dev / Stage / Prod */
"archtype":"SaaS", /* SaaS / Edge / On-Prem */
"hardware":"Dedicated", /* Classic (No extra cost allocated) / Dedicated (Extra cost allocated) */
"product":"Product-A", /* Product-A / -B / -C / -N */
"MessageAttributes": {
"event_type": {
"Type": "String",
"Value": "mycompany.producer.event.client.published" /* (Dinamic) Company.App.messageType.client.EventAction */
},
"published_on": "2023.01.2.23.02.642883101", /* +%Y.%m.%d.%H.%M.%N */
"trace_id": "9a2ae9de-3f82-4f55-966b-47df50ff51ff", /* uniq random string */
"retrace_intent": "0" /* how many reintents */
},
"Metadata": {
"host": "hostname", /* microservice */
"origing": "Cloud", /* Cloud / On-Prem */
"publisher": "producer" /* publisherType */
}
}